链接:http://data.eastmoney.com/bbsj/201903/yjbb.html

数据内容是方块,需要找到字体文件。

抓包分析,第一条是个api,可以直接获取明文数据,为研究技术这里不用这个,第三条是字体文件
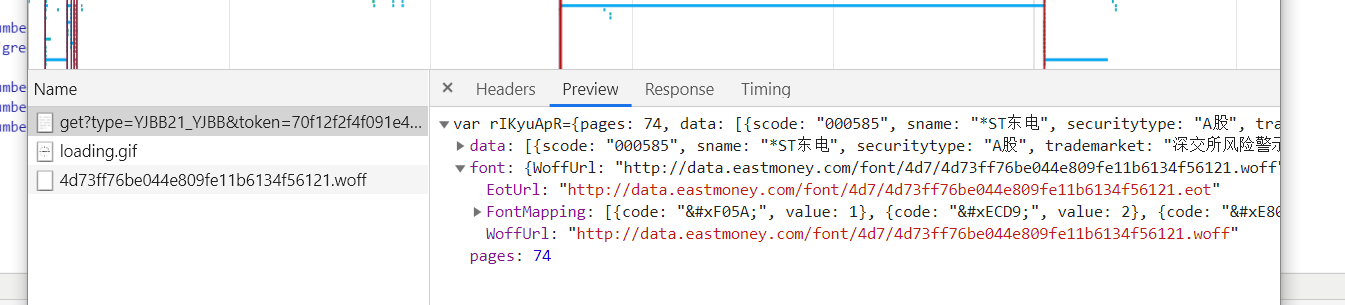
用requests请求数据,抄一遍headers,试着把get改成用post,post成功,但数字是乱码,所以需要把乱码改成数字
#把headers里的querystring抄到dada里用post发送
url="http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js"headers={
"Referer": "http://data.eastmoney.com/bbsj/201903/yjbb.html","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}data={ "type": "YJBB21_YJBB","token": "70f12f2f4f091e459a279469fe49eca5","st": "latestnoticedate","sr": "-1","p": "1","ps": "50","js": "var rIKyuApR={pages:(tp),data: (x),font:(font)}","filter": "(securitytypecode in ('058001001','058001002'))(reportdate=^2018-09-30^)","rt": "51838114"}r=requests.post(url=url,headers=headers,data=data)r.encoding=r.apparent_encodingprint(r.text)r.encoding=r.apparent_encoding
print(r.text)
#用jupyter打开比较方便
处理数据,把字符串变成字典
org_data=r.text[r.text.index("{ "):]json_str = or_data.replace('data:', '"data":').replace('pages:', '"pages":').replace('font:', '"font":')json_data = json.loads(json_str) #拿到字体文件 font_url = json_data['font']['WoffUrl']
处理结果:

字体
字体的cmap表里记录有字形索引和字形的关系,有关字体已整理记录在:
乱码原因
网站加载的自定义字体的字形索引和字形的映射关系和标准的映射关系不一样,只能用网站自定义的字体来解析,爬虫抓到的数据后用标准字体解析得到错误结果。
解决方法
建立新联系,让自定义字体的索引与标准字体的字对应,然后全局替换,这样就能正确数据。关系如下图:

找关系
用到TTFont库解析字体
font = requests.get(font_url, headers=header, timeout=30)font_name = font_url.split("/")[-1]with codecs.open(font_name, 'wb') as f: f.write(font.content)font_map = TTFont(font_name).getBestCmap()#用getBestCmap()可以得到字体index和glphy的映射关系 “”“{120: 'x', 57960: 'bgldyy', 57971: 'qqdwzl', 58817: 'whyhyx', 59299: 'wqqdzs', 60397: 'zbxtdyc', 60633: 'zwdxtdy', 60650: 'zrwqqdl', 61125: 'bdzypyc', 62069: 'sxyzdxn', 62669: 'nhpdjl'}”“” font_map里是自定义字体索引和字形的关系,key是index,value表示字形。
unicode就是index进行十六进制转化后将0X'替换成 '&#x'得来的,font_map里的index转换成unicode如下:
font_index = [hex(key).upper().replace('0X', '&#x') +';' for key in font_map.keys()] “”“['x', '', '', '', '', '', '', '', '', '', '']”“”
得到了自定义字体的关系后,还需要unicode索引和和标准字符的关系,可以自己手动找,东方财富网直接写在页面上了。
font_mapping = json_data['font']['FontMapping'] replace_dict= {i['code']: str(i['value']) for i in font_map} ”“”
{'': '7', '': '1', '': '9', '': '3', '': '4', '': '8', '': '2', '': '0', '': '6', '': '5'} ”“”
#最后直接在文章中替换,key换成value。
for k, v in replace_dict.items(): json_str = json_str.replace(k, v) finall_data = json.loads(json_str)
结果:
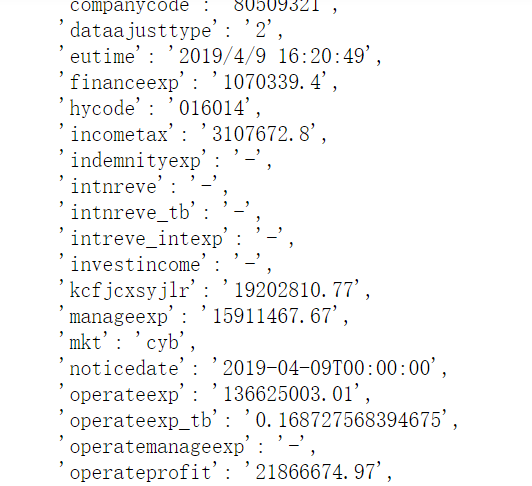
得到正确数字。
最后根据需要的字段筛选数据并将数据存入数据库,导出数据保存成csv。
